Problem: On the web, enable a large number of message producers send a very large number of messages to a much larger number of message consumers. Example: allow 100,000 publishers send a total of 1 million messages per second to 100 million concurrently connected consumers.
We are dealing with the problem of connection channels, an abstraction that allows a producer distribute the message to many connected consumers. Our challenge is to design a distributed channel delivery mechanism that can scale out to millions of connected consumers. Throughout, our assumption is that this is a stateless delivery system, i.e. messages are either delivered or dropped and no persistence guarantees exists; if a consumer is not connected, it will miss the message.
The naïve approach is to perform consistent hashing by channel. In this model, each channel and all its consumers are in the same server. Since the channel identifier is part of the URI, the load balancer can effectively perform this operation, and we can add servers as required without requiring re-balancing. When we have many channels per server, the distribution is eventually uniform. Problems arise however as some channels have an order of magnitude more consumers than other channels. There is also a problem if a channel has more consumers than a server can sustain.
To solve the limitations of hashing by channel, we can instead perform consistent hashing by channel and connection (consumer). In this model, each consumer is consistently assigned to a pool of servers and we can add servers without having to re-balance consumers among servers. The channel stores a list of all the consumer identifiers and channels are consistently hashed across servers. To deliver a message, the load balancer will find the server holding the channel, and dispatch the request. The channel will lookup the list of consumer identifiers and again apply the consistent hashing algorithm to reach all the consumers.
Although the hashing by channel and connection is conceptually simple, it
presents significant operability challenges. First, the loss of the server
holding the channel metadata and list of connected consumers will require a
watchdog cleaning up all the stale consumer connections. Second, as consumers
join in and disappear, the channel server would need to maintain a consistent
view of the list of consumers by the means of locks, with the incurred
performance degradation of very large number of consumers. Third, as more
consumers connect uniformly across the nodes, the more chattiness that will
occur. At some point, all nodes will have consumer connections for a given
channel. In order to to fulfill every operation, we must issue N requests to
all nodes, where N is the number of nodes in the cluster. For the cluster to
be able to process and deliver M messages, every node must be capable of
processing N*M messages. This design will be limited in the number of
connections it can hold, because of the centralized channel-consumer tracking
problem, and will also only scale to the maximum request processing capacity
of an individual node.
We can solve some of the operability challenges by removing the channel management of consumer connections, and instead of keeping a list, keeping the visibility of the peer nodes. Here the thinking is that since we will asymptotically reach the point where all nodes hold consumer connections for a given channel, all we really need to do is keep a list of all nodes in the cluster. Some centralized agent keeps a directory of all active peers holding consumer connections, e.g. a Zookeeper ensemble.
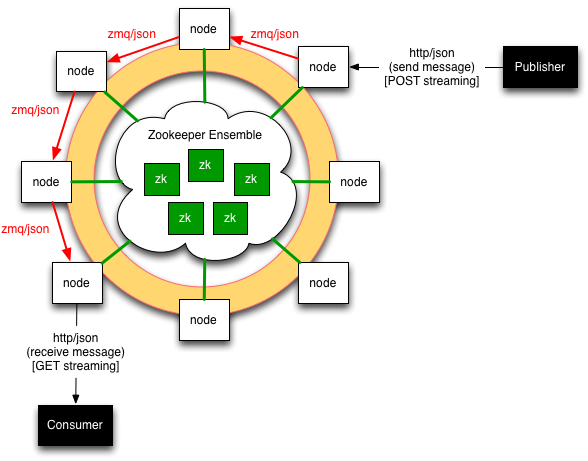
Consumers get uniformly connected to the nodes in the cluster by a “good” load-balancing scheme. Since any node can hold connections to consumers on any channel, there is therefore no snapshot of a channel’s consumers, and to be able to identify all consumers connected to a channel it is necessary to interrogate all nodes in the cluster. Whereas this design improves the previous ones in that it allows scaling to an infinite number of connections, it will still only scale to the message processing throughput of an individual node.
A popular alternative to the directory of nodes is the tree of nodes. In this model, we start with a single node. As we reach the maximum number of connections the node can hold, we add two new nodes. The original node still accepts messages from publishers, but brokers the delivery to the two new nodes. As those nodes themselves become saturated, we add a new layer of four nodes. And so forth. This approach has the same limitation as the one using a directory of nodes, i.e. the maximum throughput is bound to that of the individual node.
We’ve seen how to hold the connections to an infinite number of consumers, but not how to deliver an infinite number of messages. These solutions scale very well to tens of thousands of messages and millions of active connected consumers, but have an upper limit. For most producers out there, that upper limit is probably high enough to be fine. But such limit exists in push-based systems
Both the messaging literature and the messaging praxis have historically preferred using pull-based models rather than push-based ones. In a pull model, consumers come back to the broker to fetch messages, at each consumer’s own rate, and the problem is therefore no longer dispatching across millions of connections. Pull-based messaging systems chose to store the messages until consumers come back to fetch them. In fact, the only scalable messaging system to millions of messages and millions of consumers that we know of uses store- and-forward: SMTP.
As much as I may think that the techniques that enable web push-models such as HTTP streaming, long-poll and WebSockets are genuinely useful to solve point problems, they are not techniques we can use to implement Internet-scale push- based web services, as they are fundamentally based on a PubSub model. The scalability of PubSub under high load remains an unresolved research question and as such is not a paradigm we should apply at Internet-scale.
In fact, I am now almost convinced that we’ve been looking at this in the wrong way, and that the right solution to this problem is a store-and-forward solution, where web consumers connect at their own rate to fetch messages and intermediaries throttle concurrent connection rates in order to achieve linear scalability. Essentially, this is a web of partially connected store-and- forward almost real-time async data peers. And that’s a mouthful, but a really exciting one.
blog comments powered by Disqus